標準偏差
![]() 分散と標準偏差についての解説と求め方。標準偏差を使い投資のリスクを評価します。
分散と標準偏差についての解説と求め方。標準偏差を使い投資のリスクを評価します。
- ■VARP(数値1,数値2,・・・)
- 指定した数値や範囲内のデータを母集団として分散を計算します。空白セルや文字列は無視して計算します。
- ■STDEVP(数値1.数値2,…)
- 指定した数値や範囲内のデータを母集団全体として標準偏差を計算します。空白セルや文字列は無視して計算します。
- ■SQRT(数値)
- 指定した数値の平方根を計算します。
- ■FREQUENCY(データ配列,区間配列)
- データ配列で指定したセル範囲のデータに対して、区間配列で指定した区切りに沿って、その区間に含まれるデータの数を計算する。
ただし、配列数式として関数を入力する必要がある。
投資でいうリスクとは何か?
リスクは将来の不確実性であるといえます。またリスクの大小はバラツキの大きさであらわすことができ、標準偏差(Standard deviation)はそのバラツキをみる指標です。
つまり標準偏差の大きさを比べることで投資のリスクを評価することができます。
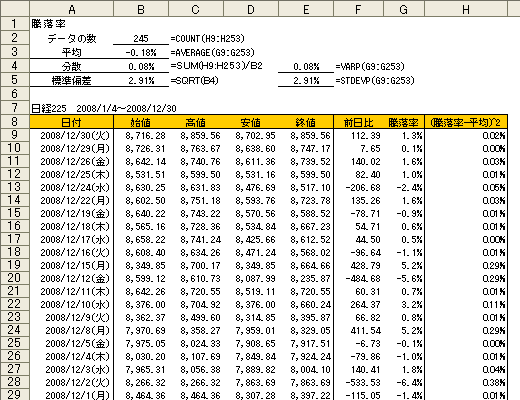
標準偏差の前にまず分散(Variance)について説明します。データは2008年の日経平均株価を使用します。
分散の求めるには、最初にリターン(騰落率)の平均(セルB3)をとります。次にそれぞれの日々リターンから平均を引きます(偏差)。
この偏差を二乗(セルH9:H253)し平均を計算したものが分散(セルB4)です。
分散はExcelではVARP関数を使い求めます。数値には騰落率を指定します。
セルE4に【=VARP(G9:G253)】と入力します。セルB4と同じ値(0.0008)が表示されます。
次にSQRT関数を使い分散の平方根を求めます。これが標準偏差(セルB5)です。
ExcelではSTDEVP関数を使います。数値には騰落率を指定します。
セルE5に【=STDEVP(G9:G253)】と入力します。セルB5と同じ値(2.91%)が表示されます。(図3-1
![]() STDEVP関数と良く似た関数にSTDEV関数があります。違いは以下になります。
STDEVP関数と良く似た関数にSTDEV関数があります。違いは以下になります。
・STDEVP関数は、引数を母集団全体であると見なします。指定する数値が母集団の標本である場合は、STDEV関数を使って計算します。
・標本数が非常に多い場合、STDEV関数と STDEVP関数の戻り値は、ほぼ同じ値になります。
偏差は各リターンと平均との差ですから単位はパーセントです。分散は偏差の二乗で求められます。つまり分散の単位はパーセントの二乗になっています。パーセントの二乗では少しイメージし難いです。そのためバラツキの指標では分散の平方根を計算した標準偏差(単位はパーセント)が一般的です。いわゆるボラティリティは標準偏差のことをさします。
標準偏差はリターンのバラツキをあらわす指標ですから、標準偏差が大きい株ほどリスクが高いといえます。
![]() 具体的に標準偏差がリスクをどう評価しているかみてみます。
具体的に標準偏差がリスクをどう評価しているかみてみます。
最初に日次リターンがどのような分布になっているか調べてみます。
ExcelのFREQUENCY関数を使い頻度分布を計算してみます。この関数は配列数式をいう特別な形で入力する必要があります。
1)データを分類するためにデータをいくつかの階級に分けます。ここでは1%刻みで31階級に分けています。
2)次にJ9:J39の範囲を選択し、セルJ9に【=FREQUENCY(G9:G253,J9:J39)】と入力します。
データ配列は騰落率全体、区間配列は設定した階級を指定します。
3)ここでコントロールキーとシフトキーを押しながら同時にエンターキーを押します(【Ctrl】+【Shift】+【Enter】)。
これで頻度分布が作成できます。(図3-2
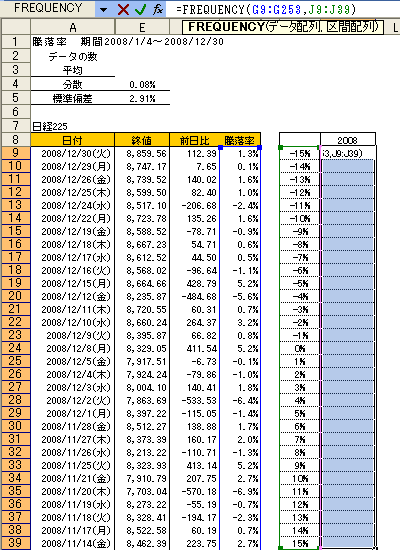
これで階級ごとの頻度が表示されました。これをグラフにすると統計学でいう正規分布曲線に似た分布図が出てきます。(図3-3
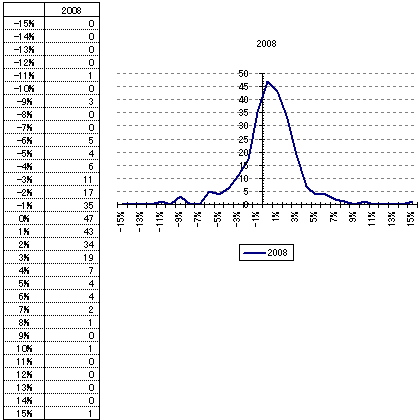
2008年は100年に一度といわれる金融危機に陥り株式相場は大荒れでした。
このときの標準偏差(σ)は2.91%です。一方、1978年〜2007年の標準偏差を求めてみると1.21%です。
比べてみれば2008年の標準偏差が大きくリスクが高かったことがわかります。
ただこのままでは少しわかりにくいので表現を変えてみます。正規分布曲線では±1σに入る確率は68.26%、±2σでは95.44%です。
統計学的にいえば、2008年は前日比±2.91%(±1σ)以上変動した日が全体の32%ありますが、1978年〜2007年では前日比で±2.42%以上(±2σ)変動した日は全体の4.6%しかなかったことになります。
また、縦軸を相対度数(度数を全体の個数で割ったもの)にした分布図は下のようになります。(図3-4
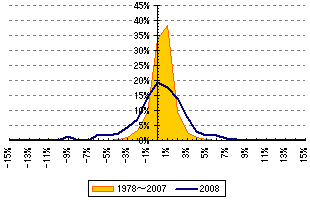
これらのことから標準偏差がリスクを表し、いかに2008年が大荒れだったかがわかると思います。
ただし実際に2008年で前日比±2.91%以上変動した日は53日(全体の21.6%)でした。また、1978年〜2007年で前日比±2.42%以上変動した日は434日と全体の5.6%でした。
次は、標準偏差とリターンの関係です。
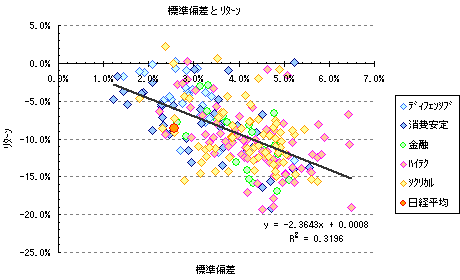
日経平均採用銘柄をセクター別に分類し、横軸に標準偏差、縦軸にリターンを取り散布図を作ってみました。
直線は単回帰線です。
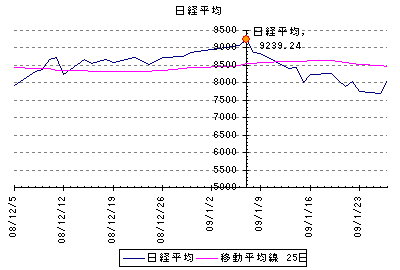
最初の散布図は、2009年1月7日が基準です。
標準偏差の算出期間は25日、リターンは7日後の1月14日の株価と比較したときの騰落率です。
この間日経平均株価は、9239.24円から8438.45円へと800.79円(8.7%)下落しています。
次の散布図は、2009年3月31日が基準です。
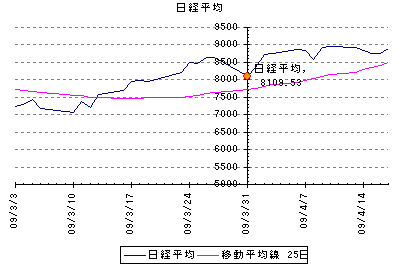
標準偏差の算出期間は25日、リターンは7日後の4月7日の株価と比較したときの騰落率です。
この間日経平均株価は、8109.53円から8832.85円へと723.32円(8.9%)上昇しています。
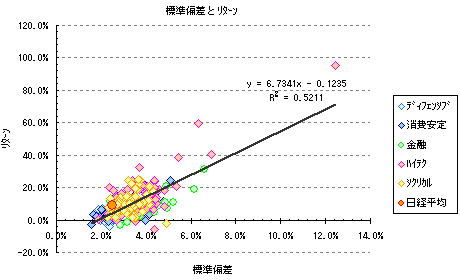
前者では標準偏差が高いほどリターンは減少し、後者では標準偏差が高いほどリターンが増加しています。
つまりハイリスク・ハイリターンということです。
セクター別では、やはりディフェンシブや消費安定株がローリスク・ローリターン、ハイテク株がハイリスク・ハイリターンとなっています。
また、グラフの左上にある銘柄ほどローリスク・ハイリターン、右下のほどハイリスク・ローリターンとなります。
Excelに戻る
相関係数
![]() 相関係数についての解説と求め方。
相関係数についての解説と求め方。
- ■VARP(数値1,数値2,・・・)
- 指定した数値や範囲内のデータを母集団として分散を計算します。空白セルや文字列は無視して計算します。
- ■COVAR(配列1.配列数値2)
- 指定した数値や範囲内のデータから共分散を計算します。空白セルや文字列は無視して計算します。
- ■CORREL(配列1.配列数値2)
- 指定した数値や範囲内のデータから相関係数を計算します。空白セルや文字列は無視して計算します。
まず分散(Variance)を求めます。分散はバラツキをあらわす統計量でExcel関数ではVARP関数で求めます。
次に共分散(Covariance)を求めますが定義の数式はわかりにくいので省略します。
共分散の基本的な考え方は、変数XとYの偏差を掛けたものの期間平均です。EXCEL関数ではCOVAR関数を使えば簡単に求めることができます。
Cov=COVAR(Xの騰落率,Yの騰落率)
・共分散は値が正の場合、Xのリターンが平均を超える時、Yのリターンも平均を上回ります。また、Xのリターンが平均を下回る時は、Yも平均を下回ります。つまり共分散は2変数の相関関係の方向を示す指標です。ただし相関の強弱を示しているわけではないです。
相関係数ρ(Correlation)は共分散を2つの変数の標準偏差の積で割って求めます。EXCEL関数だとCORREL関数を使います。
ρ=CORREL(Xの騰落率,Yの騰落率)
相関係数は2つの変数の相関の強さを表し、必ず-1〜1の間になります。
基本的な性質は以下
・相関係数>0 → 2つの変数は同じ方向に動きます。
・相関係数=0 → 2つの変数はまったく無関係に動きます。
・相関係数<0 → 2つの変数は反対方向に動きます。
また相関係数は一般的に次のように言われています。(図3-9
期間100日の国際石油開発とファーストリテイリングの各パラメータです。(図3
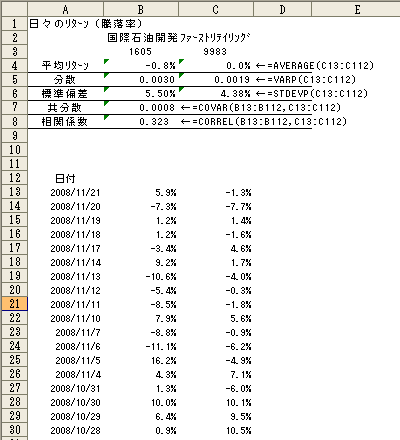
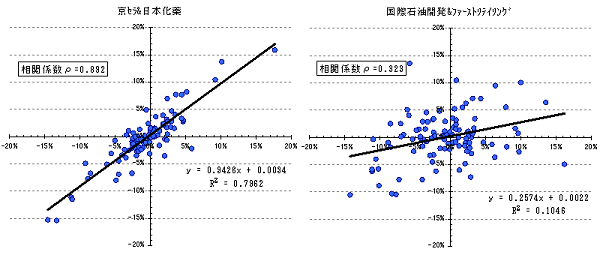
図4は相関係数の違いが散布図にどう表れるかを示しています。 相関関係の弱い国際石油開発とファーストリテイリングの散布図が比較的ばらばらなのに対して相関関係の強い京セラと日本化薬のものは点が右肩上がりになっているのがわかります。
Excelに戻る 次のページへ