回帰分析
![]() Excel関数と散布図を使い回帰分析について解説しています。
Excel関数と散布図を使い回帰分析について解説しています。
- ■INTERCEPT(既知のy,既知のx)
- 既知の y と既知の x のデータから回帰直線の切片を求めます。
- ■SLOPE(既知のy,既知のx)
- 既知の y と既知の x のデータから回帰直線の傾きを求めます。
- ■RSQ(既知のy,既知のx)
- 既知の y と既知の x を通過する回帰直線を対象にした決定係数を求めます。
回帰分析は、説明する変数(説明変数)xと説明される変数(被説明変数)yの効果の大きさを調べたり、予測をしたりするための手法です。簡単に言えば2つの変数の関係を一次方程式にあてはめて分析する手法です。
当てはまりの良い線を引く方法は、点と線の差分の二乗の総和を最小化する最小二乗法を使います。
一次方程式はy=ax+bの形であらわせますが傾きaに対応するのがβ、切片bがαとなります。ここでは日本水産と日経225の直近50日のデータを下に回帰分析をしてみました。
■α(Alpha)
大雑把にいえばx(日経平均株価)に対する超過収益(厳密には超過収益はリスクフリーレートで調整する必要がありますがここでは省略します)
・α>0ではy(個別銘柄)のパフォーマンスが期待以上。
・α<0ではパフォーマンスが期待以下となります。
■β(Beta)
x(日経平均株価)のリターンが1%変化したした時に、y(個別銘柄)のリターンが何%変化するかという感応度。
・β>1では市場平均よりも大きく動く傾向があります。
・β<1では市場平均よりも小さく動く傾向があります。
・βがマイナスの株式では市場平均と反対に動く傾向があります。
■R2(R-squared)決定係数
変数 y(個別銘柄)の変動を変数X(日経平均株価)の変動で説明可能な部分の割合を表します。 70%を超えると相関関係が強いといえます。
ここではB列に日経平均の騰落率(x)、C列に日本水産の騰落率(y)を入力し2つの関係を調べてみます。まず、グラフ機能で散布図を作成します。次にグラフの点をマークしたまま右クリックし【近似曲線の追加】を選択します。そして線形近似を選択し、タブで次ページに移動した後【グラフに数式を表示する】と【グラフにR-2乗値を表示する】をチェックします。これで近似線が引け数式が表示されます。
この結果、グラフの直線はy=0.9008x-0.0015、決定係数は64.89%であることがわかります。(図3-1
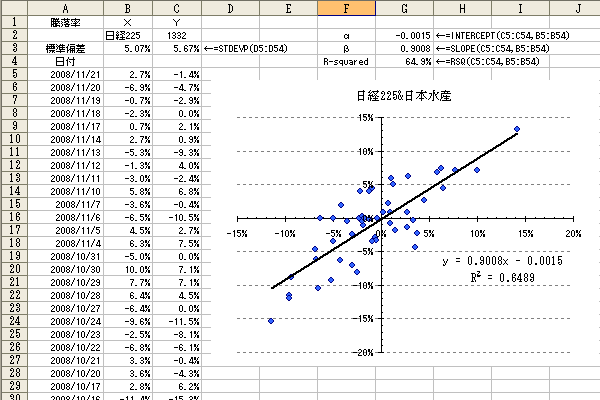
日本水産のβ値は0.9008です。このことは日経平均が1%上昇すると日本水産株は平均0.9008%上昇することを意味してます。また、1より小さいということは日本水産株は日経平均に対して感応度が低いということになります。
一方、α値は-0.0015なのでこの期間日本水産は日経平均のパフォーマンスを下回っていたことになります。
またR2(決定係数)が64.89%であるということは、日本水産のパフォーマンスの64.89%は日経225のパフォーマンスで説明できることを示してます。
これをExcel関数で求める場合の数式は、
セルG2、α=INTERCEPT(yの騰落率,xの騰落率)
セルG3、β=SLOPE(yの騰落率,xの騰落率)
セルG4、R2=RSQ(yの騰落率,xの騰落率)となります。
回帰分析を行う場合、2つの項目の中でとちらをxとして、どちらをyとするか分かりにくい場合があります。
その場合、次のように考えます。
1.結果となるものをy、原因となるものをxとする。
2.影響を受けるものをy、影響を及ぼすものをxとする。
3.先に発生するものをx、後から発生するものをyとする。
日経平均株価は採用銘柄の平均株価なので上記に照らすと、日本水産の騰落率がxで日経平均の騰落率がyになると考えることもできますが、ここではマーケット全体(日経平均)が日本水産の株式に与える影響を分析したいので日本水産をy、日経平均をxとしています。
Excelに戻る
重回帰分析1
![]() Excelのアドイン機能、分析ツールを利用した重回帰分析の説明。
Excelのアドイン機能、分析ツールを利用した重回帰分析の説明。
このアドインを使えばエクセルでも重回帰分析が使えるようになります。
単回帰分析では変数は1つですが、この機能で独立変数を最大16個まで設定することができます。
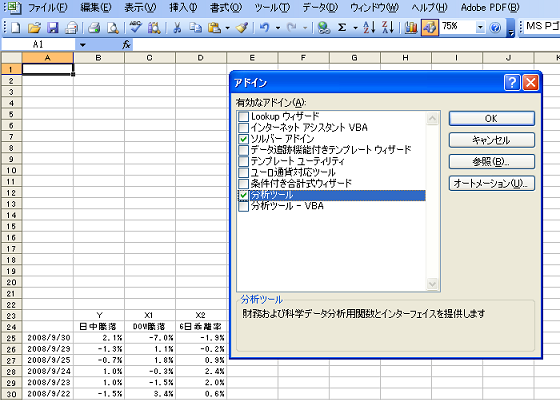
ツールメニューの中に分析ツールがない場合はアドイン登録をします。
アドイン登録は、ソルバーと同様の手順です。メニューバーから【ツール】→【アドイン】をクリックし追加できるアドインの中から【分析ツール】のチェックボックスをオンにしてOKをクリックします。(図3-2
分析前の注意点ですが、変数Xは隣り合ったセルとしラベル(名称)をつけておく必要があります。また、解析範囲から空白セルは除いておかないとエラーがでます。
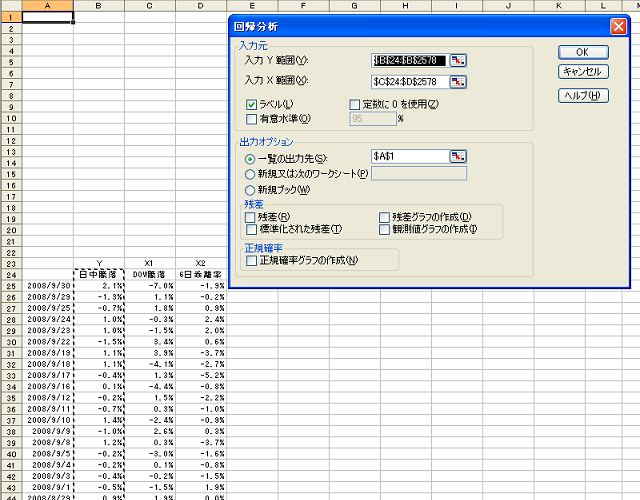
ここではDOW騰落率と6日移動平均乖離率から翌日の日中騰落率を回帰分析してみます。
【ツール】→【分析ツール】をクリックし回帰分析を選択します。設定画面が表示されたら入力Y範囲と入力X範囲を設定しラベルの項目のチェックをいれます。
次に出力オプションで出力先を設定してOKをクリックします。一覧の出力先を指定する場合、データは既存のセルに上書きされます。また、【戻る】のコマンドも効かなくなるので出力先には注意が必要です。(図3-3
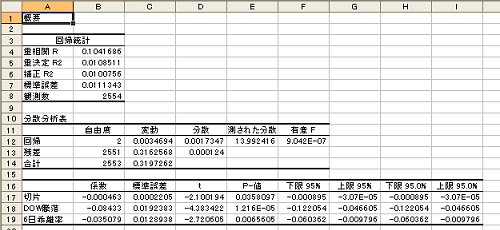
分析結果(図3-4
![]() 簡単な用語説明
簡単な用語説明
| 【重決定R2】 | 回帰分析の当てはまりの指標で、y の偏差平方和のうちby の偏差平方和によって説明できる割合を示します。 |
| 【補正R2】 | 自由度修正決定係数を示し説明変数の数を考慮した当てはまりの指標です。 決定係数は説明変数の数がたとえ無関係な変数でも増やすほど増加します。この影響を考慮したものが補正R2となります。 |
| 【標準誤差】 | エラーの平均的なばらつきの推定値です。 |
| 【分散分析表】 | 切片以外の全ての説明変数は無効(切片以外の説明変数の真の係数は全て0である)という帰無仮説の検定を行っています。【観測された分散比】は決定係数が大きいほど大きくなります。この値が大きければ帰無仮説は 不自然となります。【有意F】は帰無仮説のもとで、偶然によって標本が観測されてしまう確率の上限を示しています。低いほど効果のある説明変数があることになります。 |
| 【係数】 | 被説明変数への効果の推定値。 |
| 【標準誤差】 | 係数の不確かさを示します。係数の標準誤差が小さいと、推定精度が高いことになります。 説明変数のエラー(回帰分析で説明できない部分)のばらつきが大きいときや説明変数同士が相関を持つ場合は標準誤差は大きくなります。 |
| 【P-値】 | 係数が0となる確率です。帰無仮説のもとで、分析結果のt 値が出る境目の確率を示しています。0.05を切っていることが目安となります。当然、低いほうが好ましいです。 |
| 【t】 | t 値は標準誤差で割ることで基準精度で評価した推定係数。t分布を示しており回帰式のあてはまり具合を示しています。目安として絶対値で2を超えれば効果のある説明変数といえます。 |
決定係数は0.0103511となり日中騰落を求める重回帰式はY=−0.08433×DOW(X1)−0.035079×乖離率(X2)−0.000463(切片)となることがわかります。
求めた推定式はt値が2を超えておりP-値も0.05以下となっています。有意Fも低い値ですので回帰式として成立していると思われます。
きちんと勉強したい方は
![]() 統計学自習ノートの重回帰分析や
統計学自習ノートの重回帰分析や![]() てくてくGISさんの演習の中にわかりやすい説明があるのでそちらをどうぞ。
てくてくGISさんの演習の中にわかりやすい説明があるのでそちらをどうぞ。
Excelに戻る
Excelに戻る 次のページへ