廳夞婣暘愅俀
![]() 悢検壔棟榑嘥椶傪棙梡偟偰廳夞婣暘愅傪偟傑偡丅
悢検壔棟榑嘥椶傪棙梡偟偰廳夞婣暘愅傪偟傑偡丅
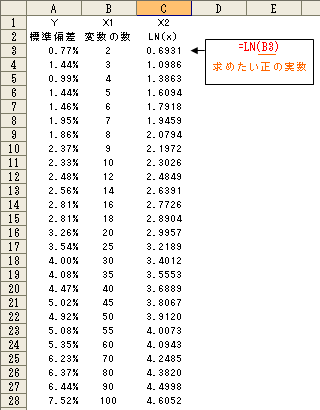
丂慜夞巊偭偨僨乕僞傪巊梡偟偰悢検壔棟榑嘥椶傪棙梡偟偨廳夞婣暘愅傪偍偙側偄傑偡丅 悢検壔棟榑嘥椶偼梛擔傗揤婥側偳掕惈揑側僨乕僞傪巊偭偰旐愢柧曄悢傪愢柧偡傞幃傪媮傔傑偡丅 寧丄壩側偳僇僥僑儕傪悢抣壔偡傞偨傔偵掕惈揑僨乕僞傪0丄1偱昞尰偟側偍偟傑偡丅偙傟傪僟儈乕曄悢偲尵偄傑偡丅 僇僥僑儕偵奩摉偡傞応崌偼1丄奩摉偟側偄応崌偵0傪擖傟傑偡丅
丂僟儈乕曄悢偺椺乮恾3-5
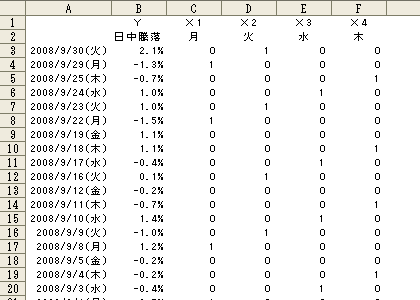
梛擔僨乕僞偼寧梛擔偐傜嬥梛擔傑偱偁傝傑偡偑丄寧梛擔乣栘梛擔傑偱偺忣曬偑偁傟偽嬥梛擔偺僨乕僞偼悇應偱偒傞偨傔嬥梛擔偺楍偼嶍彍偟偰偍偒傑偡丅
慜夞巊梡偟偨僨乕僞傪巊偄幚嵺偵廳夞婣暘愅傪偟偰傒傑偡丅
愢柧曄悢乮傾僀僥儉乯偼丄DOW摣棊棪+0.2%埲忋丄-0.2%埲壓傪掕惈揑僨乕僞丄6擔摣棊棪傪掕検揑僨乕僞偲偟偰庢傝埖偄傑偡丅乮恾3-6
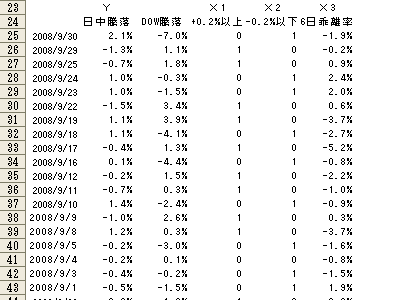
丂暘愅寢壥乮恾3-7
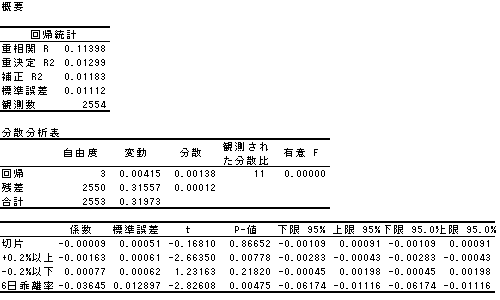
丂寛掕學悢偼0.011398偲側傝傑偡丅
傑偨丄擔拞摣棊傪媮傔傞廳夞婣幃偼倄亖亅0.00163亊+0.2%埲忋(倃1乯+0.00077亊-0.2%埲壓乮倃2乯-0.03645亊槰棧棪乮倃3乯亅0.00009乮愗曅乯偲側傞偙偲偑傢偐傝傑偡丅
丂尦偼摨偠僨乕僞偱偡偑丄僟儈乕曄悢傪巊梡偟偨傕偺偲掕検揑僨乕僞偺傑傑偱廳夞婣暘愅傪偟偨偺偱偼寢壥偼偐側傝堎側偭偰偒傑偡丅嬶懱揑側堘偄偼丄
![]() 僔僗僥儉僩儗乕僪乣僄僢僕偺崌惉偱僔僗僥儉偺惈擻僠僃僢僋傪偟偰偄傑偡偺偱嶲峫偵偟偰偔偩偝偄丅
僔僗僥儉僩儗乕僪乣僄僢僕偺崌惉偱僔僗僥儉偺惈擻僠僃僢僋傪偟偰偄傑偡偺偱嶲峫偵偟偰偔偩偝偄丅
Excel偵栠傞
廳夞婣暘愅俁
![]() 帺慠懳悢傗懡崁幃傪棙梡偟偰廳夞婣暘愅傪偍偙側偄傑偡丅
帺慠懳悢傗懡崁幃傪棙梡偟偰廳夞婣暘愅傪偍偙側偄傑偡丅
- ■LN(悢抣)
- 悢抣偺帺慠懳悢傪媮傔傑偡丅悢抣偼惓偺幚悢抣傪巜掕偟傑偡丅
- ■POWER(悢抣,巜悢)
- 悢抣偵偼傋偒忔偺掙傪巜掕偟傑偡丅擟堄偺幚悢傪巜掕偟傑偡丅
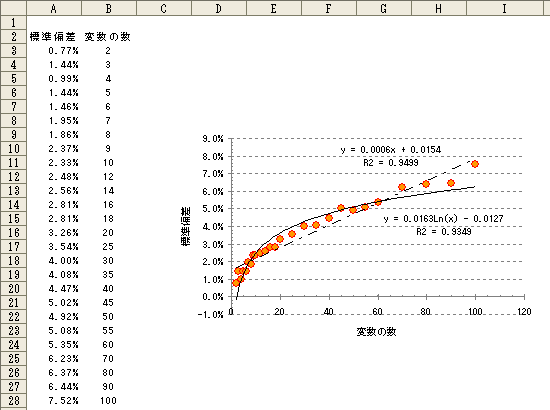
丂嶶晍恾偐傜媮傔傜傟傞嬤帡幃傪棙梡偡傟偽帺慠懳悢傗懡崁幃偺扨夞婣暘愅偼偱偒傑偡丅 偟偐偟丄慄宍偲帺慠懳悢丄帺慠懳悢偲懡崁幃偺傛偆側応崌偵偼僌儔僼偐傜媮傔傞偙偲偼偱偒傑偣傫丅 偙偺応崌偼丄暘愅僣乕儖偺夞婣暘愅傪棙梡偟傑偡丅
丂幚嵺偵廳夞婣暘愅傪偟偰傒傑偡丅倄幉偼昗弨曃嵎丄倃幉偼曄悢偺悢偱偡丅
僨乕僞偼![]() 僄僢僕奣榑偱巊梡偟偨傕偺偱偡丅乮恾3-8
僄僢僕奣榑偱巊梡偟偨傕偺偱偡丅乮恾3-8
塃懁僌儔僼偼丄僨乕僞傪嶶晍恾偵偟偨傕偺偲僌儔僼婡擻偱慄宍嬤帡丄懳悢嬤帡傪捛壛偟偨傕偺偱偡丅
![]() 慄宍偲帺慠懳悢
慄宍偲帺慠懳悢
丂嵟弶偵丄曄悢偺帺慠懳悢傪媮傔偰偍偒傑偡丅帺慠懳悢偼LN娭悢傪巊偄媮傔傑偡丅
僙儖C3偵亂=LN(B3)亃偲擖椡偟壓偺僙儖偵僐僺乕偟傑偡丅乮恾3-9
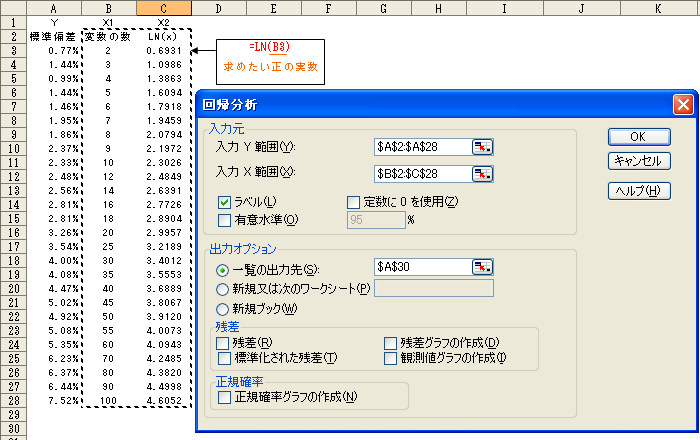
丂師偵暘愅僣乕儖傪巊偄廳夞婣暘愅傪偍偙側偄傑偡丅擖椡倄斖埻偼亂$A2:$A$28亃丄擖椡倃斖埻偼亂 $B$2:$C$28亃傪巜掕偟傑偡丅儔儀儖偵僠僃僢僋傪偄傟弌椡愭傪巜掕偟亂俷俲亃傪僋儕僢僋偟傑偡丅乮恾3-10
丂暘愅寢壥乮恾3-11
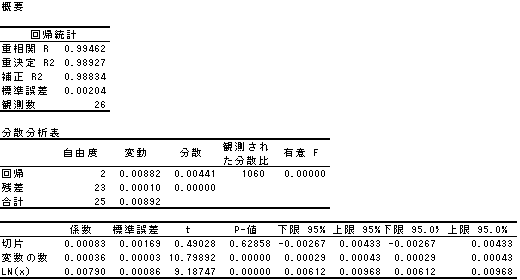
丂寛掕學悢偼0.98927偲扨夞婣暘愅偺偲偒傛傝傕岦忋偟偰偄傑偡丅
傑偨丄廳夞婣幃乮惵慄乯偼倄亖0.00036亊曄悢偺悢乮倃1乯亄0.00790亊LN(倃2乯亄0.00083乮愗曅乯偲側傝傑偡丅(恾3-9
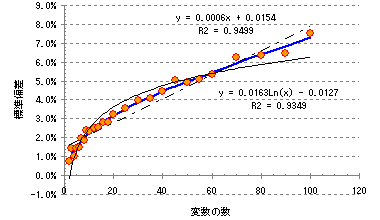
![]() 帺慠懳悢偲傋偒忔
帺慠懳悢偲傋偒忔
丂嵟弶偵丄曄悢偺傋偒忔傪媮傔偰偍偒傑偡丅傋偒忔偼亂悢抣^巜悢亃傕偟偔偼POWER娭悢傪巊偄媮傔傑偡丅
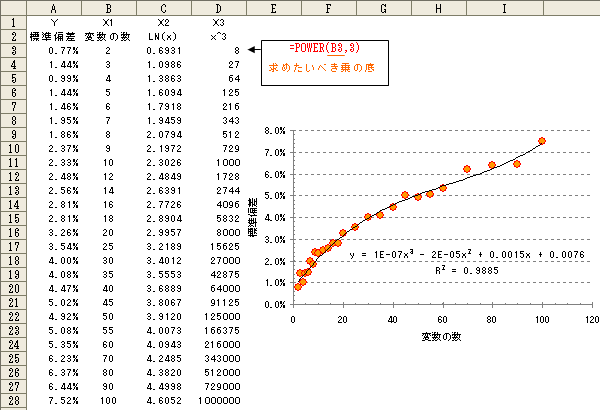
僙儖D3偵亂=POWER(B3,3)亃偲擖椡偟壓偺僙儖偵僐僺乕偟傑偡丅乮恾3-13
塃懁僌儔僼偼丄僌儔僼婡擻偱懡崁幃嬤帡乮師悢3乯傪捛壛偟偨傕偺偱偡丅
丂
丂師偵暘愅僣乕儖傪巊偄廳夞婣暘愅傪偍偙側偄傑偡丅擖椡倄斖埻偼亂$A2:$A$28亃丄擖椡倃斖埻偼亂 $B$2:$D$28亃傪巜掕偟傑偡丅
丂暘愅寢壥乮恾3-8
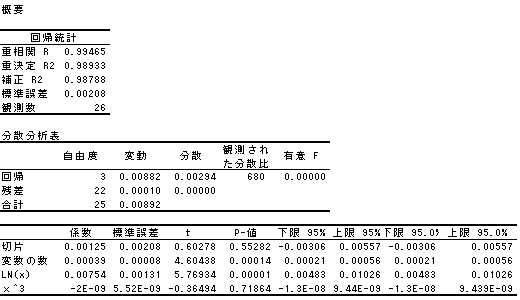
丂寛掕學悢偼0.98933偲帺慠懳悢偺偲偒傛傝傕庒姳岦忋偟偰偄傑偡丅
傑偨丄廳夞婣幃偼倄亖0.00039亊曄悢偺悢乮倃1乯亄0.00754亊LN(倃2乯亄0.00754亊X^3(倃3乯亄0.00083乮愗曅乯偲側傝傑偡丅
丂寛掕學悢偩偗傪斾妑偟偨応崌丄屻幰偺廳夞婣暘愅偺傎偆偑偄偄偱偡丅
偟偐偟丄幚嵺偵屻幰偺曽偑嵟揔側夞婣幃偐偳偆偐偼暿偺榖偱偡丅側偤側傜丄愢柧曄悢傪憹傗偡傎偳寛掕學悢偑椙偔側傞偙偲偑懡偄偨傔偱偡丅
丂偦偙偱桳岠側愢柧曄悢偐偳偆偐傪敾抐偡傞偨傔偺巜昗偲偟偰愢柧曄悢慖戰婎弨乮俼倳乯傪棙梡偟傑偡丅
俼倳偼埲壓偺幃偱昞偝傟傑偡丅
丂丂俼倳亖侾亅乮侾亅R2乯亊乮僨乕僞悢亄愢柧曄悢偺屄悢亄侾乯亐乮僨乕僞悢亅愢柧曄悢偺屄悢亅侾乯
嬶懱揑偵寁嶼偟偰傒傑偡丅
丂丒慜幰乮愢柧曄悢2偮乯丂Ru=1-(1-0.98927)*(26+2+1)/(26-2-1)=0.98647
丂丒屻幰乮愢柧曄悢3偮乯丂Ru=1-(1-0.98933)*(26+3+1)/(26-3-1)=0.98545
偲側傝慜幰偺曽偑Ru偼傛偔側傝傑偡丅傛偭偰慜幰偺曽偑傛傝傛偄夞婣幃偲偄偆偙偲偵側傝傑偡丅
愢柧曄悢偑暋悢偁傞応崌偼丄偡傋偰偺僷僞乕儞偱Ru傪媮傔Ru偑嵟戝偲側傞慻崌偣傪嵟揔側夞婣幃偲偟傑偡丅
Excel偵栠傞